This article is more than one year old. Older articles may contain outdated content. Check that the information in the page has not become incorrect since its publication.
Kubernetes 1.16: Custom Resources, Overhauled Metrics, and Volume Extensions
We’re pleased to announce the delivery of Kubernetes 1.16, our third release of 2019! Kubernetes 1.16 consists of 31 enhancements: 8 enhancements moving to stable, 8 enhancements in beta, and 15 enhancements in alpha.
Major Themes
Custom resources
CRDs are in widespread use as a Kubernetes extensibility mechanism and have been available in beta since the 1.7 release. The 1.16 release marks the graduation of CRDs to general availability (GA).
Overhauled metrics
Kubernetes has previously made extensive use of a global metrics registry to register metrics to be exposed. By implementing a metrics registry, metrics are registered in more transparent means. Previously, Kubernetes metrics have been excluded from any kind of stability requirements.
Volume Extension
There are quite a few enhancements in this release that pertain to volumes and volume modifications. Volume resizing support in CSI specs is moving to beta which allows for any CSI spec volume plugin to be resizable.
Significant Changes to the Kubernetes API
As the Kubernetes API has evolved, we have promoted some API resources to stable, others have been reorganized to different groups. We deprecate older versions of a resource and make newer versions available in accordance with the API versioning policy.
An example of this is the Deployment resource. This was introduced under the extensions/v1beta1 group in 1.6 and as the project changed has been promoted to extensions/v1beta2, apps/v1beta2 and finally promoted to stable and moved to apps/v1 in 1.9.
It's important to note that until this release the project has not stopped serving any of the previous versions of the any of the deprecated resources.
This means that folks interacting with the Kubernetes API have not been required to move to the new version of any of the deprecated API objects.
In 1.16 if you submit a Deployment to the API server and specify extensions/v1beta1 as the API group it will be rejected with:
error: unable to recognize "deployment": no matches for kind "Deployment" in version "extensions/v1beta1"
With this release we are taking a very important step in the maturity of the Kubernetes API, and are no longer serving the deprecated APIs. Our earlier post Deprecated APIs Removed In 1.16: Here’s What You Need To Know tells you more, including which resources are affected.
Additional Enhancements
Custom Resources Reach General Availability
CRDs have become the basis for extensions in the Kubernetes ecosystem. Started as a ground-up redesign of the ThirdPartyResources prototype, they have finally reached GA in 1.16 with apiextensions.k8s.io/v1, as the hard-won lessons of API evolution in Kubernetes have been integrated. As we transition to GA, the focus is on data consistency for API clients.
As you upgrade to the GA API, you’ll notice that several of the previously optional guard rails have become required and/or default behavior. Things like structural schemas, pruning unknown fields, validation, and protecting the *.k8s.io group are important for ensuring the longevity of your APIs and are now much harder to accidentally miss. Defaulting is another important part of API evolution and that support will be on by default for CRD.v1. The combination of these, along with CRD conversion mechanisms are enough to build stable APIs that evolve over time, the same way that native Kubernetes resources have changed without breaking backward-compatibility.
Updates to the CRD API won’t end here. We have ideas for features like arbitrary subresources, API group migration, and maybe a more efficient serialization protocol, but the changes from here are expected to be optional and complementary in nature to what’s already here in the GA API. Happy operator writing!
Details on how to work with custom resources can be found in the Kubernetes documentation.
Opening Doors With Windows Enhancements
Beta: Enhancing the workload identity options for Windows containers
Active Directory Group Managed Service Account (GMSA) support is graduating to beta and certain annotations that were introduced with the alpha support are being deprecated. GMSA is a specific type of Active Directory account that enables Windows containers to carry an identity across the network and communicate with other resources. Windows containers can now gain authenticated access to external resources. In addition, GMSA provides automatic password management, simplified service principal name (SPN) management, and the ability to delegate the management to other administrators across multiple servers.
Adding support for RunAsUserName as an alpha release. The RunAsUserName is a string specifying the windows identity (or username) in Windows to run the entrypoint of the container and is a part of the newly introduced windowsOptions component of the securityContext (WindowsSecurityContextOptions).
Alpha: Improvements to setup & node join experience with kubeadm
Introducing alpha support for kubeadm, enabling Kubernetes users to easily join (and reset) Windows worker nodes to an existing cluster the same way they do for Linux nodes. Users can utilize kubeadm to prepare and add a Windows node to cluster. When the operations are complete, the node will be in a Ready state and able to run Windows containers. In addition, we will also provide a set of Windows-specific scripts to enable the installation of prerequisites and CNIs ahead of joining the node to the cluster.
Alpha: Introducing support for Container Storage Interface (CSI)
Introducing CSI plugin support for out-of-tree providers, enabling Windows nodes in a Kubernetes cluster to leverage persistent storage capabilities for Windows-based workloads. This significantly expands the storage options of Windows workloads, adding onto a list that included FlexVolume and in-tree storage plugins. This capability is achieved through a host OS proxy that enables the execution of privileged operations on the Windows node on behalf of containers.
Introducing Endpoint Slices
The release of Kubernetes 1.16 includes an exciting new alpha feature: the EndpointSlice API. This API provides a scalable and extensible alternative to the Endpoints resource, which dates back to the very first versions of Kubernetes. Behind the scenes, Endpoints play a big role in network routing within Kubernetes. Each Service endpoint is tracked within these resources - kube-proxy uses them for generating proxy rules that allow pods to communicate with each other so easily in Kubernetes, and many ingress controllers use them to route HTTP traffic directly to pods.
Providing Greater Scalability
A key goal for EndpointSlices is to enable greater scalability for Kubernetes Services. With the existing Endpoints API, a single instance must include network endpoints representing all pods matching a Service. As Services start to scale to thousands of pods, the corresponding Endpoints resources become quite large. Simply adding or removing one endpoint from a Service at this scale can be quite costly. As the Endpoints instance is updated, every piece of code watching Endpoints will need to be sent a full copy of the resource. With kube-proxy running on every node in a cluster, a copy needs to be sent to every single node. At a small scale, this is not an issue, but it becomes increasingly noticeable as clusters get larger.
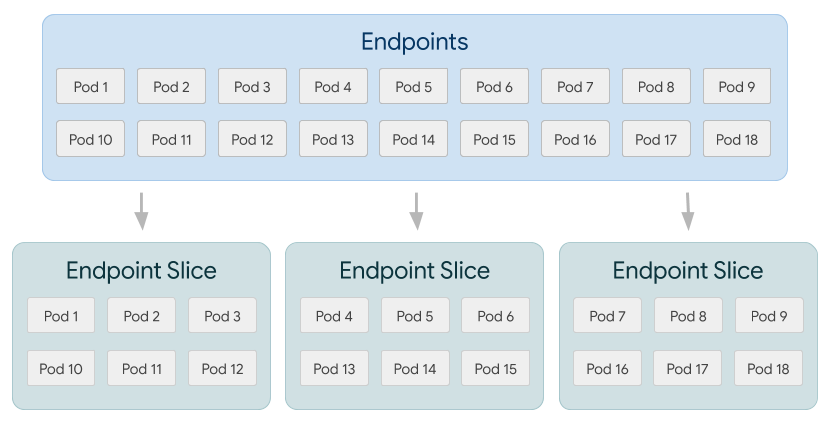
With EndpointSlices, network endpoints for a Service are split into multiple instances, significantly decreasing the amount of data required for updates at scale. By default, EndpointSlices are limited to 100 endpoints each.
For example, let’s take a cluster with 10,000 Service endpoints spread over 5,000 nodes. A single Pod update would result in approximately 5GB transmitted with the Endpoints API (that’s enough to fill a DVD). This becomes increasingly significant given how frequently Endpoints can change during events like rolling updates on Deployments. The same update will be much more efficient with EndpointSlices since each one includes only a tiny portion of the total number of Service endpoints. Instead of transferring a big Endpoints object to each node, only the small EndpointSlice that’s been changed has to be transferred. In this example, EndpointSlices would decrease data transferred by approximately 100x.
| Endpoints | Endpoint Slices | |
| # of resources | 1 | 20k / 100 = 200 |
| # of network endpoints stored | 1 * 20k = 20k | 200 * 100 = 20k |
| size of each resource | 20k * const = ~2.0 MB | 100 * const = ~10 kB |
| watch event data transferred | ~2.0MB * 5k = 10GB | ~10kB * 5k = 50MB |
Providing Greater Extensibility
A second goal for EndpointSlices was to provide a resource that would be highly extensible and useful across a wide variety of use cases. One of the key additions with EndpointSlices involves a new topology attribute. By default, this will be populated with the existing topology labels used throughout Kubernetes indicating attributes such as region and zone. Of course, this field can be populated with custom labels as well for more specialized use cases.
EndpointSlices also include greater flexibility for address types. Each contains a list of addresses. An initial use case for multiple addresses would be to support dual-stack endpoints with both IPv4 and IPv6 addresses. As an example, here’s a simple EndpointSlice showing how one could be represented:
apiVersion: discovery.k8s.io/v1alpha
kind: EndpointSlice
metadata:
name: example-abc
labels:
kubernetes.io/service-name: example
addressType: IP
ports:
- name: http
protocol: TCP
port: 80
endpoints:
- addresses:
- "10.1.2.3"
- "2001:db8::1234:5678"
topology:
kubernetes.io/hostname: node-1
topology.kubernetes.io/zone: us-west2-a
More About Endpoint Slices
EndpointSlices are an alpha feature in Kubernetes 1.16 and not enabled by default. The Endpoints API will continue to be enabled by default, but we’re working to move the largest Endpoints consumers to the new EndpointSlice API. Notably, kube-proxy in Kubernetes 1.16 includes alpha support for EndpointSlices.
The official Kubernetes documentation contains more information about EndpointSlices as well as how to enable them in your cluster. There’s also a great KubeCon talk that provides more background on the initial rationale for developing this API.
Notable Feature Updates
- Topology Manager, a new Kubelet component, aims to co-ordinate resource assignment decisions to provide optimized resource allocations.
- IPv4/IPv6 dual-stack enables the allocation of both IPv4 and IPv6 addresses to Pods and Services.
- Extensions for Cloud Controller Manager Migration.
Availability
Kubernetes 1.16 is available for download on GitHub. To get started with Kubernetes, check out these interactive tutorials. You can also easily install 1.16 using kubeadm.
Release Team
This release is made possible through the efforts of hundreds of individuals who contributed both technical and non-technical content. Special thanks to the release team led by Lachlan Evenson, Principal Program Manager at Microsoft. The 32 individuals on the release team coordinated many aspects of the release, from documentation to testing, validation, and feature completeness.
As the Kubernetes community has grown, our release process represents an amazing demonstration of collaboration in open source software development. Kubernetes continues to gain new users at a rapid pace. This growth creates a positive feedback cycle where more contributors commit code creating a more vibrant ecosystem. Kubernetes has had over 32,000 individual contributors to date and an active community of more than 66,000 people.
Release Mascot
The Kubernetes 1.16 release crest was loosely inspired by the Apollo 16 mission crest. It represents the hard work of the release-team and the community alike and is an ode to the challenges and fun times we shared as a team throughout the release cycle. Many thanks to Ronan Flynn-Curran of Microsoft for creating this magnificent piece.

Kubernetes Updates
Project Velocity
The CNCF has continued refining DevStats, an ambitious project to visualize the myriad contributions that go into the project. K8s DevStats illustrates the breakdown of contributions from major company contributors, as well as an impressive set of preconfigured reports on everything from individual contributors to pull request lifecycle times. This past year, 1,147 different companies and over 3,149 individuals contribute to Kubernetes each month. Check out DevStats to learn more about the overall velocity of the Kubernetes project and community.
Ecosystem
- The Kubernetes project leadership created the Security Audit Working Group to oversee the very first third-part Kubernetes security audit, in an effort to improve the overall security of the ecosystem.
- The Kubernetes Certified Service Providers program (KCSP) reached 100 member companies, ranging from the largest multinational cloud, enterprise software, and consulting companies to tiny startups.
- The first Kubernetes Project Journey Report was released, showcasing the massive growth of the project.
KubeCon + CloudNativeCon
The Cloud Native Computing Foundation’s flagship conference gathers adopters and technologists from leading open source and cloud native communities in San Diego, California from November 18-21, 2019. Join Kubernetes, Prometheus, Envoy, CoreDNS, containerd, Fluentd, OpenTracing, gRPC, CNI, Jaeger, Notary, TUF, Vitess, NATS, Linkerd, Helm, Rook, Harbor, etcd, Open Policy Agent, CRI-O, and TiKV as the community gathers for four days to further the education and advancement of cloud native computing. Register today!
Webinar
Join members of the Kubernetes 1.16 release team on Oct 22, 2019 to learn about the major features in this release. Register here.
Get Involved
The simplest way to get involved with Kubernetes is by joining one of the many Special Interest Groups (SIGs) that align with your interests. Have something you’d like to broadcast to the Kubernetes community? Share your voice at our weekly community meeting, and through the channels below. Thank you for your continued feedback and support.
- Follow us on Twitter @Kubernetesio for latest updates
- Join the community discussion on Discuss
- Join the community on Slack
- Post questions (or answer questions) on Stack Overflow
- Share your Kubernetes story