This article is more than one year old. Older articles may contain outdated content. Check that the information in the page has not become incorrect since its publication.
Feature Highlight: CPU Manager
This blog post describes the CPU Manager, a beta feature in Kubernetes. The CPU manager feature enables better placement of workloads in the Kubelet, the Kubernetes node agent, by allocating exclusive CPUs to certain pod containers.
Sounds Good! But Does the CPU Manager Help Me?
It depends on your workload. A single compute node in a Kubernetes cluster can run many pods and some of these pods could be running CPU-intensive workloads. In such a scenario, the pods might contend for the CPU resources available in that compute node. When this contention intensifies, the workload can move to different CPUs depending on whether the pod is throttled and the availability of CPUs at scheduling time. There might also be cases where the workload could be sensitive to context switches. In all the above scenarios, the performance of the workload might be affected.
If your workload is sensitive to such scenarios, then CPU Manager can be enabled to provide better performance isolation by allocating exclusive CPUs for your workload.
CPU manager might help workloads with the following characteristics:
- Sensitive to CPU throttling effects.
- Sensitive to context switches.
- Sensitive to processor cache misses.
- Benefits from sharing a processor resources (e.g., data and instruction caches).
- Sensitive to cross-socket memory traffic.
- Sensitive or requires hyperthreads from the same physical CPU core.
Ok! How Do I use it?
Using the CPU manager is simple. First, enable CPU manager with the Static policy in the Kubelet running on the compute nodes of your cluster. Then configure your pod to be in the Guaranteed Quality of Service (QoS) class. Request whole numbers of CPU cores (e.g., 1000m, 4000m) for containers that need exclusive cores. Create your pod in the same way as before (e.g., kubectl create -f pod.yaml). And voilà, the CPU manager will assign exclusive CPUs to each of container in the pod according to their CPU requests.
apiVersion: v1
kind: Pod
metadata:
name: exclusive-2
spec:
containers:
- image: quay.io/connordoyle/cpuset-visualizer
name: exclusive-2
resources:
# Pod is in the Guaranteed QoS class because requests == limits
requests:
# CPU request is an integer
cpu: 2
memory: "256M"
limits:
cpu: 2
memory: "256M"
Pod specification requesting two exclusive CPUs.
Hmm … How Does the CPU Manager Work?
For Kubernetes, and the purposes of this blog post, we will discuss three kinds of CPU resource controls available in most Linux distributions. The first two are CFS shares (what's my weighted fair share of CPU time on this system) and CFS quota (what's my hard cap of CPU time over a period). The CPU manager uses a third control called CPU affinity (on what logical CPUs am I allowed to execute).
By default, all the pods and the containers running on a compute node of your Kubernetes cluster can execute on any available cores in the system. The total amount of allocatable shares and quota are limited by the CPU resources explicitly reserved for kubernetes and system daemons. However, limits on the CPU time being used can be specified using CPU limits in the pod spec. Kubernetes uses CFS quota to enforce CPU limits on pod containers.
When CPU manager is enabled with the "static" policy, it manages a shared pool of CPUs. Initially this shared pool contains all the CPUs in the compute node. When a container with integer CPU request in a Guaranteed pod is created by the Kubelet, CPUs for that container are removed from the shared pool and assigned exclusively for the lifetime of the container. Other containers are migrated off these exclusively allocated CPUs.
All non-exclusive-CPU containers (Burstable, BestEffort and Guaranteed with non-integer CPU) run on the CPUs remaining in the shared pool. When a container with exclusive CPUs terminates, its CPUs are added back to the shared CPU pool.
More Details Please ...
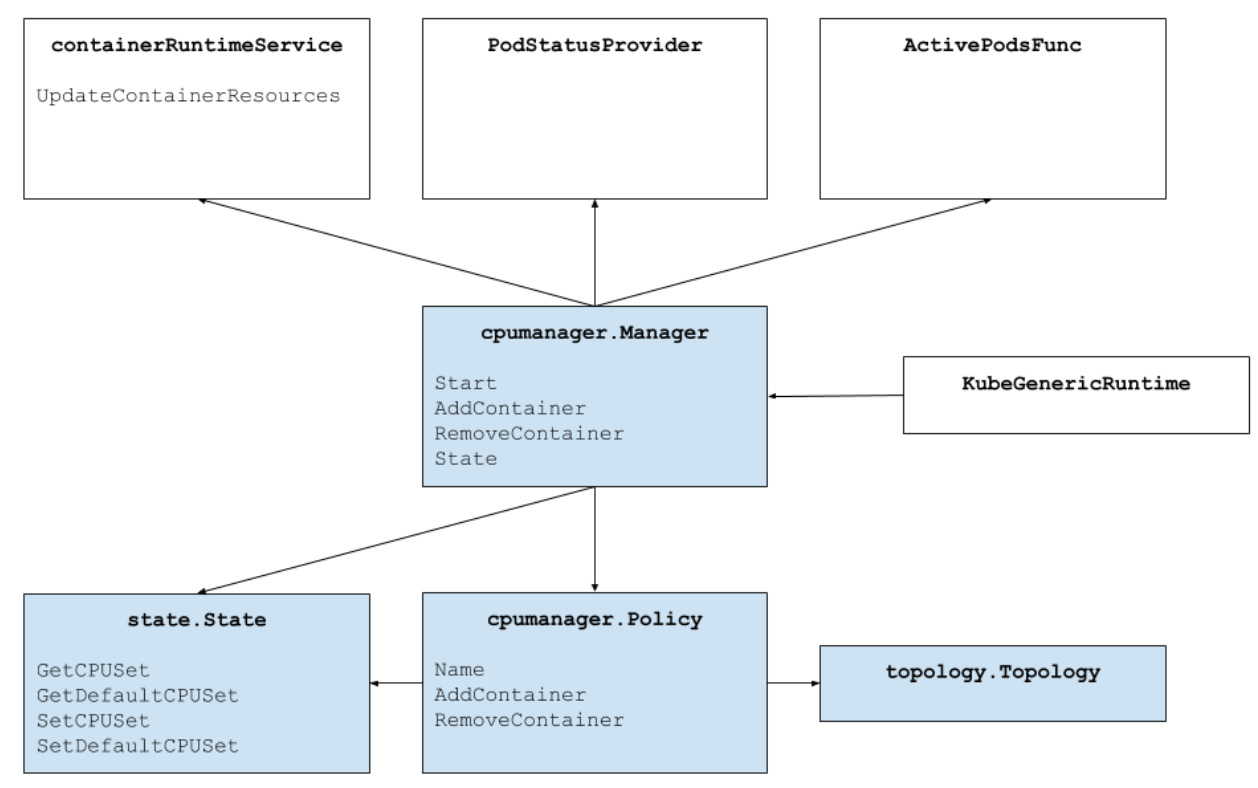
The figure above shows the anatomy of the CPU manager. The CPU Manager uses the Container Runtime Interface's UpdateContainerResources method to modify the CPUs on which containers can run. The Manager periodically reconciles the current State of the CPU resources of each running container with cgroupfs.
The CPU Manager uses Policies to decide the allocation of CPUs. There are two policies implemented: None and Static. By default, the CPU manager is enabled with the None policy from Kubernetes version 1.10.
The Static policy allocates exclusive CPUs to pod containers in the Guaranteed QoS class which request integer CPUs. On a best-effort basis, the Static policy tries to allocate CPUs topologically in the following order:
- Allocate all the CPUs in the same processor socket if available and the container requests at least an entire socket worth of CPUs.
- Allocate all the logical CPUs (hyperthreads) from the same physical CPU core if available and the container requests an entire core worth of CPUs.
- Allocate any available logical CPU, preferring to acquire CPUs from the same socket.
How is Performance Isolation Improved by CPU Manager?
With CPU manager static policy enabled, the workloads might perform better due to one of the following reasons:
- Exclusive CPUs can be allocated for the workload container but not the other containers. These containers do not share the CPU resources. As a result, we expect better performance due to isolation when an aggressor or a co-located workload is involved.
- There is a reduction in interference between the resources used by the workload since we can partition the CPUs among workloads. These resources might also include the cache hierarchies and memory bandwidth and not just the CPUs. This helps improve the performance of workloads in general.
- CPU Manager allocates CPUs in a topological order on a best-effort basis. If a whole socket is free, the CPU Manager will exclusively allocate the CPUs from the free socket to the workload. This boosts the performance of the workload by avoiding any cross-socket traffic.
- Containers in Guaranteed QoS pods are subject to CFS quota. Very bursty workloads may get scheduled, burn through their quota before the end of the period, and get throttled. During this time, there may or may not be meaningful work to do with those CPUs. Because of how the resource math lines up between CPU quota and number of exclusive CPUs allocated by the static policy, these containers are not subject to CFS throttling (quota is equal to the maximum possible cpu-time over the quota period).
Ok! Ok! Do You Have Any Results?
Glad you asked! To understand the performance improvement and isolation provided by enabling the CPU Manager feature in the Kubelet, we ran experiments on a dual-socket compute node (Intel Xeon CPU E5-2680 v3) with hyperthreading enabled. The node consists of 48 logical CPUs (24 physical cores each with 2-way hyperthreading). Here we demonstrate the performance benefits and isolation provided by the CPU Manager feature using benchmarks and real-world workloads for three different scenarios.
How Do I Interpret the Plots?
For each scenario, we show box plots that illustrates the normalized execution time and its variability of running a benchmark or real-world workload with and without CPU Manager enabled. The execution time of the runs are normalized to the best-performing run (1.00 on y-axis represents the best performing run and lower is better). The height of the box plot shows the variation in performance. For example if the box plot is a line, then there is no variation in performance across runs. In the box, middle line is the median, upper line is 75th percentile and lower line is 25th percentile. The height of the box (i.e., difference between 75th and 25th percentile) is defined as the interquartile range (IQR). Whiskers shows data outside that range and the points show outliers. The outliers are defined as any data 1.5x IQR below or above the lower or upper quartile respectively. Every experiment is run ten times.
Protection from Aggressor Workloads
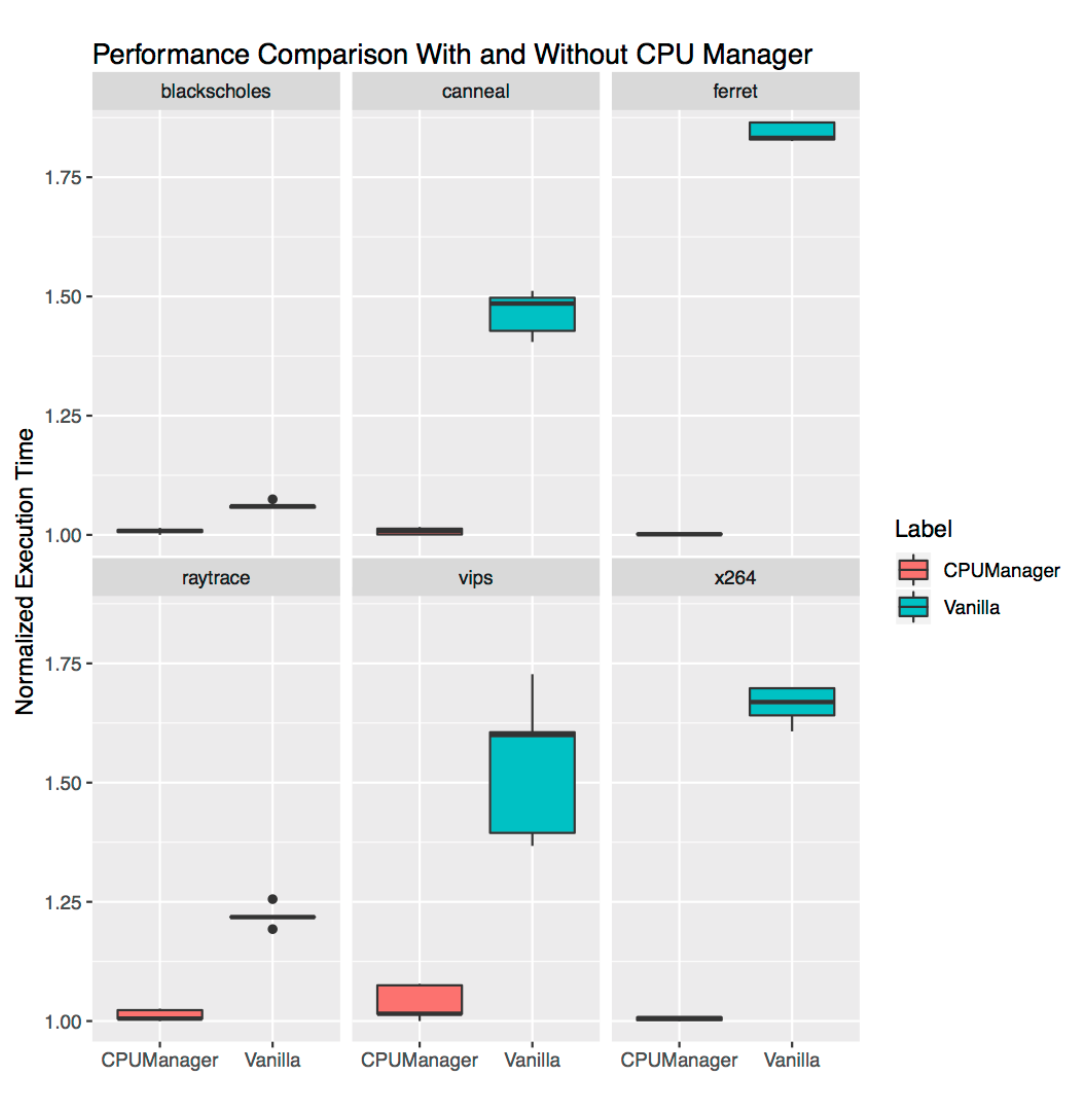
We ran six benchmarks from the PARSEC benchmark suite (the victim workloads) co-located with a CPU stress container (the aggressor workload) with and without the CPU Manager feature enabled. The CPU stress container is run as a pod in the Burstable QoS class requesting 23 CPUs with --cpus 48 flag. The benchmarks are run as pods in the Guaranteed QoS class requesting a full socket worth of CPUs (24 CPUs on this system). The figure below plots the normalized execution time of running a benchmark pod co-located with the stress pod, with and without the CPU Manager static policy enabled. We see improved performance and reduced performance variability when static policy is enabled for all test cases.
Performance Isolation for Co-located Workloads
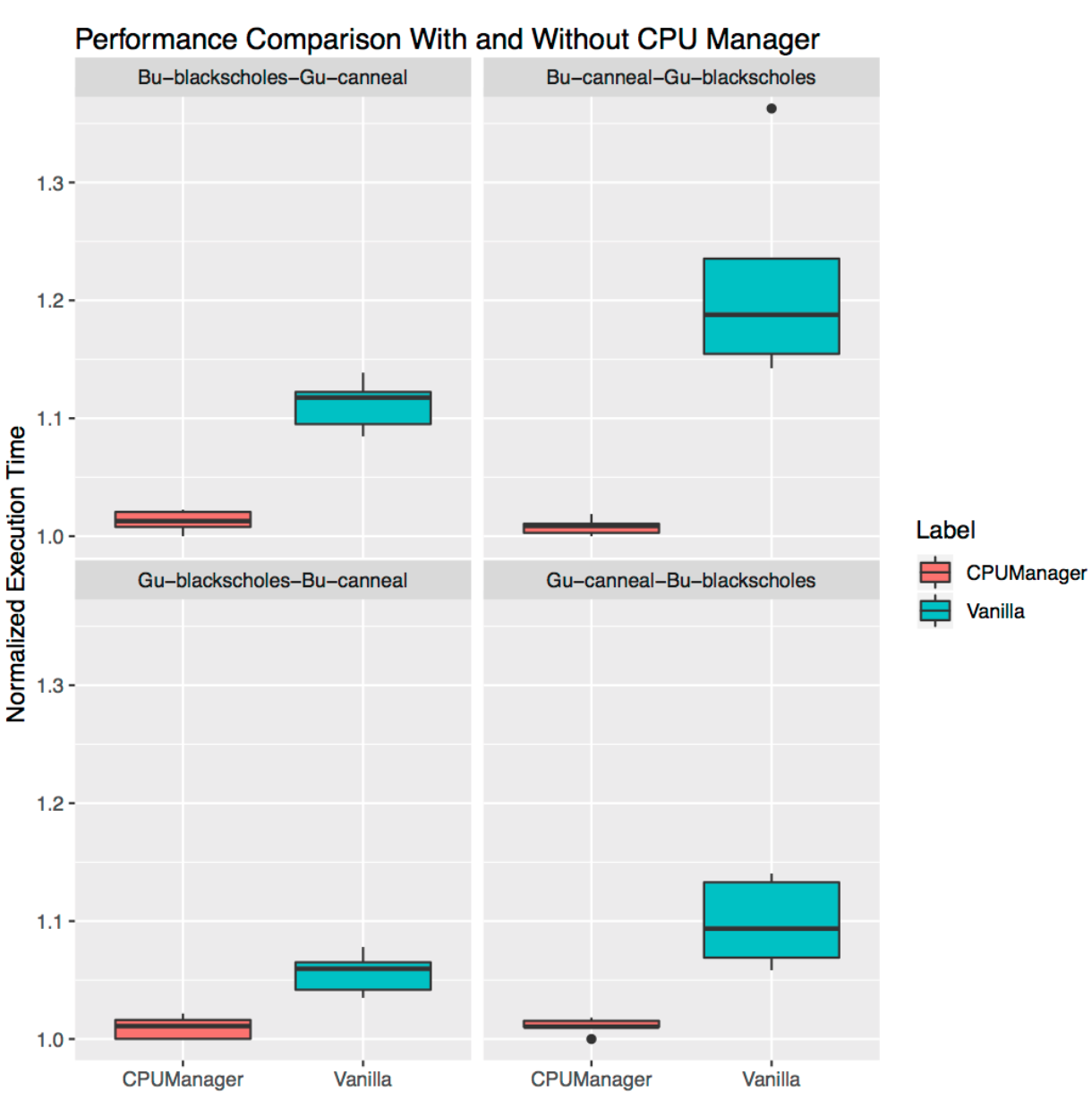
In this section, we demonstrate how CPU manager can be beneficial to multiple workloads in a co-located workload scenario. In the box plots below we show the performance of two benchmarks (Blackscholes and Canneal) from the PARSEC benchmark suite run in the Guaranteed (Gu) and Burstable (Bu) QoS classes co-located with each other, with and without the CPU manager static policy enabled.
Starting from the top left and proceeding clockwise, we show the performance of Blackscholes in the Bu QoS class (top left), Canneal in the Bu QoS class (top right), Canneal in Gu QoS class (bottom right) and Blackscholes in the Gu QoS class (bottom left, respectively. In each case, they are co-located with Canneal in the Gu QoS class (top left), Blackscholes in the Gu QoS class (top right), Blackscholes in the Bu QoS class (bottom right) and Canneal in the Bu QoS class (bottom left) going clockwise from top left, respectively. For example, Bu-blackscholes-Gu-canneal plot (top left) is showing the performance of Blackscholes running in the Bu QoS class when co-located with Canneal running in the Gu QoS class. In each case, the pod in Gu QoS class requests cores worth a whole socket (i.e., 24 CPUs) and the pod in Bu QoS class request 23 CPUs.
There is better performance and less performance variation for both the co-located workloads in all the tests. For example, consider the case of Bu-blackscholes-Gu-canneal (top left) and Gu-canneal-Bu-blackscholes (bottom right). They show the performance of Blackscholes and Canneal run simultaneously with and without the CPU manager enabled. In this particular case, Canneal gets exclusive cores due to CPU manager since it is in the Gu QoS class and requesting integer number of CPU cores. But Blackscholes also gets exclusive set of CPUs as it is the only workload in the shared pool. As a result, both Blackscholes and Canneal get some performance isolation benefits due to the CPU manager.
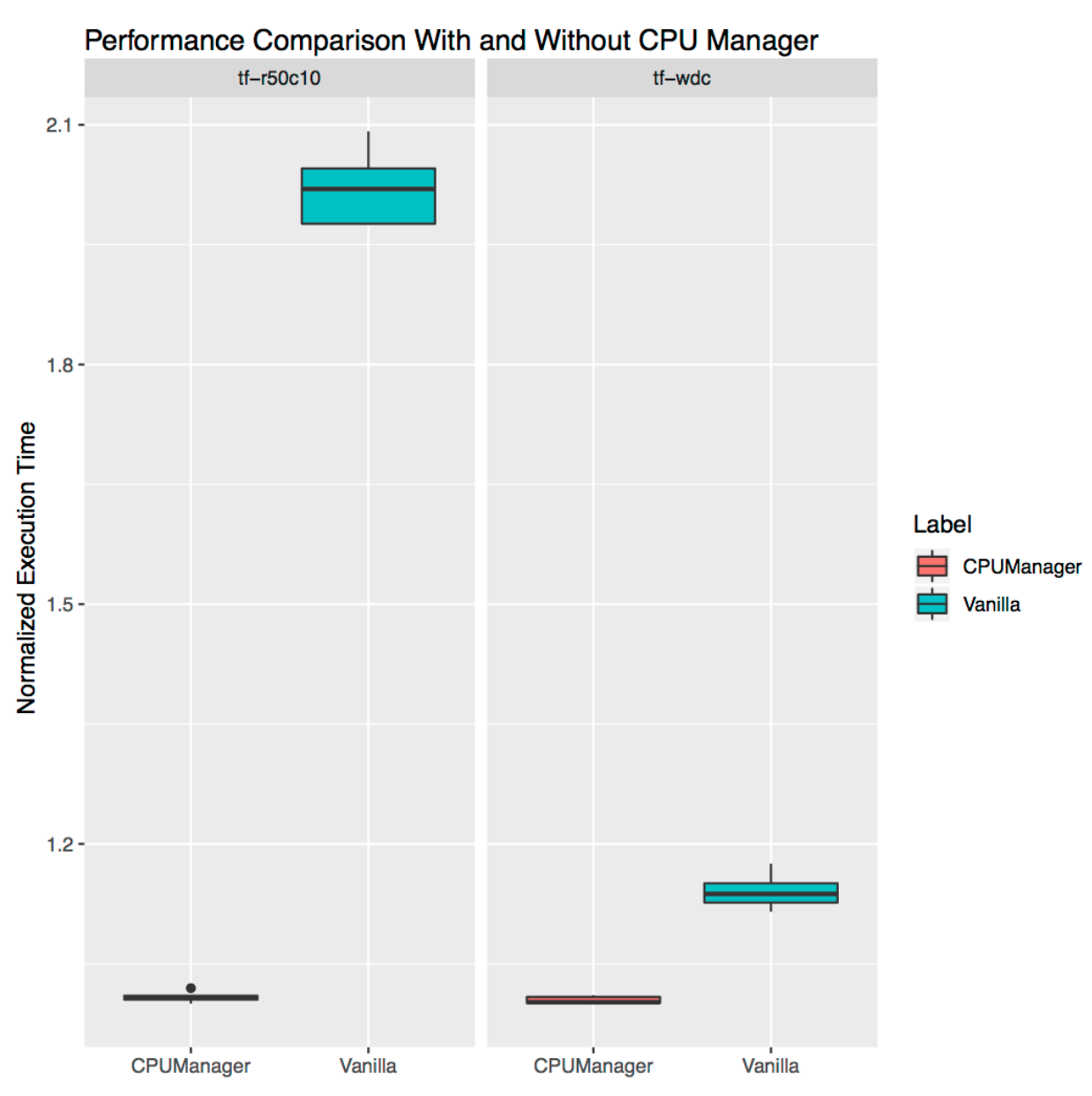
Performance Isolation for Stand-Alone Workloads
This section shows the performance improvement and isolation provided by the CPU manager for stand-alone real-world workloads. We use two workloads from the TensorFlow official models: wide and deep and ResNet. We use the census and CIFAR10 dataset for the wide and deep and ResNet models respectively. In each case the pods (wide and deep, ResNet request 24 CPUs which corresponds to a whole socket worth of cores. As shown in the plots, CPU manager enables better performance isolation in both cases.
Limitations
Users might want to get CPUs allocated on the socket near to the bus which connects to an external device, such as an accelerator or high-performance network card, in order to avoid cross-socket traffic. This type of alignment is not yet supported by CPU manager. Since the CPU manager provides a best-effort allocation of CPUs belonging to a socket and physical core, it is susceptible to corner cases and might lead to fragmentation. The CPU manager does not take the isolcpus Linux kernel boot parameter into account, although this is reportedly common practice for some low-jitter use cases.
Acknowledgements
We thank the members of the community who have contributed to this feature or given feedback including members of WG-Resource-Management and SIG-Node. cmx.io (for the fun drawing tool).
Notices and Disclaimers
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more information go to www.intel.com/benchmarks.
Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. No computer system can be absolutely secure. Check with your system manufacturer or retailer or learn more at intel.com.
Workload Configuration: https://gist.github.com/balajismaniam/fac7923f6ee44f1f36969c29354e3902 https://gist.github.com/balajismaniam/7c2d57b2f526a56bb79cf870c122a34c https://gist.github.com/balajismaniam/941db0d0ec14e2bc93b7dfe04d1f6c58 https://gist.github.com/balajismaniam/a1919010fe9081ca37a6e1e7b01f02e3 https://gist.github.com/balajismaniam/9953b54dd240ecf085b35ab1bc283f3c
System Configuration: CPU Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 48 On-line CPU(s) list: 0-47 Thread(s) per core: 2 Core(s) per socket: 12 Socket(s): 2 NUMA node(s): 2 Vendor ID: GenuineIntel Model name: Intel(R) Xeon(R) CPU E5-2680 v3 Memory 256 GB OS/Kernel Linux 3.10.0-693.21.1.el7.x86_64
Intel, the Intel logo, Xeon are trademarks of Intel Corporation or its subsidiaries in the U.S. and/or other countries.
*Other names and brands may be claimed as the property of others.
© Intel Corporation.